프로그래밍 언어는 언어 구문(syntax)과 언어 의미로 구성된다.
모두 자연어로 기술 될 수 있으며, 실제로 프로그래밍 언어 초창기에는 영어 표현으로
기술했다. 언어 의미는 아직까지도 대부분 영어로 기술되는 반면, 구문은 거의
초창기부터 사용되고 있는 형식시스템이 제공된다.
- 언어 정의(def): 구문(syntax), 의미(semantics)
- 자연어 정의, 형식화된 표현법 정의
- 구문 형식 정의 - BNF, EBNF(BNF확장), 구문 도표
- 컴퓨터라는 프로그램을 실행 할 수 있는 알고리즘+자료구조 집합
- 하드웨어 컴퓨터(실제 컴퓨터)
- 스프트웨어 시뮬레이트 컴퓨터(software simulated computer)
- 가상 컴퓨터(virtual computer)
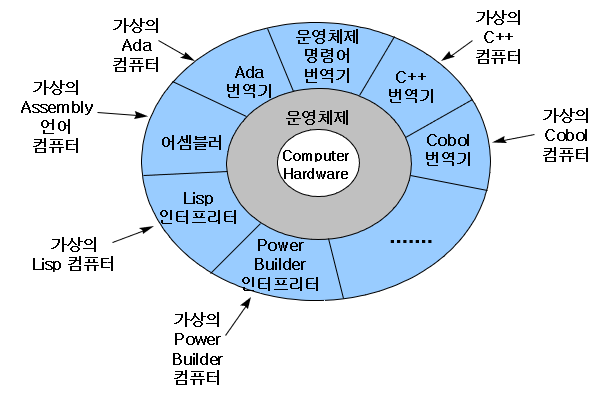
가상 컴퓨터
고급 언어 프로그래머는 컴퓨터를 가상의 고급 언어 컴퓨터로 간주
프로그래밍 언어의 기본 문자 집합
- 알파벳 문자(A-Z) 26개 + 아라비아 숫자(0-9) 10개
예) Fortran: 기본 문자 집합 + 13개의 특수문자(= + - * / ( ) , . $ ' : 공백)포함
Algol 60: 알파벳 대소문자 52개 + 아라비아 숫자 10개 + 28개의 특수문자
| relational | < | ≤ | = | > | ≥ | ≠ |
| boolean | ¬ | ∧ | ∨ | ⊃ | ≡ | |
| arithmetic | ↑ | x | + | - | ||
| special | , | ∨ | 10 | : | ; | ' |
| special | Б | ( | ) | [ | ] | " |
| Algol60의 특수 문자 | ||||||
언어 구문
- 문자 코드 체계
- EBCDIC (Extended Binary Coded Decimal Interchange Code)
- IBM에서 제안, 8비트 조합 코드
- ASCII (American Standard Code for Information Interchange)
- ANSI에서 제안, 7비트 조합 코드(128개의 문자 표현)
- 영문자 대소문자 52개 + 숫자 10개 + 33개의 특수문자 + 33개의 제어문자
- 유니 코드 (Uni code)
- 16 bit
- ISO표준 규격
- Java에 시행
- 정합 순서(collating sequence)
- 언어에 제공된 문자 순서
일반적인 순서를 지킴.
예) 0 < 1< 2 < 3 < 4 < 5 < 6 < 7 < 8 < 9
A < B < C < . . . < X < Y < Z
특수 문자 순서: 아스키코드의 2진수 참조 - 코드 체계 따름 (구현시 결정)
- 프로그래머 정의 가능 (RPG, Snobol)
- 언어에 제공된 문자 순서
- 어휘 구조 용어
- 어휘 토큰
- 언어 구성자
- 식별자, 미리 정의 된 식별자, 예약어
- 구분자, 분리자
- 어휘 토큰(lexical token), 어휘 요소(lexical element), 어휘 단어(lexical unit)
프로그래밍 언어에서 사용하는 단어의 종류 - 언어 구성자(language construct)
프로그래밍 언어의 규칙에 따라서 한 개 이상의 어휘 토큰으로 형성된다. - 식별자(indentifier)
언어 구성자를 명명하는 어휘 토큰
예) 변수, 배열, 레코드, 레이블, 프로시저 등의 이름 - 미리 정의된 식별자(predefined identifier)
번역 과정의 속도를 높여주고 프로그램의 신뢰성을 향상시키기 위하여
프로그래밍 언어에서 일부 식별자를 미리 정의하여 사용한다. 이를 미리
정의된 식별자라 한다.
예) C: scanf, printf, strcnp, #define - 예약어
위의 미리 정의된 식별자중 일부를 재 정의할 수 없도록 정의하는 것
프로그램의 변수 이름으로 사용할 수 없다.
예) C: if, while, int, ...
- 장점: 프로그램 판독성 증가, 컴파일러가 기호 테이블을 빠른 시간에 탐색
- 단점: 많은 예약어를 기억하기 어려움
언어 확장시 새로운 예약어가 확장 이전에 사용했던 프로그램의
식별자와 중복 우려
BNF (Backus – Naur Form) 표기법
- 구문(syntax) 형식을 정의하는 가장 보편적인 표기법
- 한 언어의 구문에 대한 BNF 정의는 생성 규칙(production rule)들의 집합 정의된
언어로 작성 가능한 모든 정상적인 프로그램을 이 생성 규칙들을 가지고 산출하는
것이 이론적으로 가능 - 생성 규칙
- 생성 규칙의 왼쪽(정의될 대상): 시작기호, 오른쪽에는 그 대상에 대한 정의가 표현
- 작성된 프로그램이 구문에 맞는 프로그램인지 아닌지를 인식하기 위한 구문
규율로도 사용
- BNF 표기법에 의한 식별자(identifier: 변수나 함수의 이름)정의
|
<identifier> ::= <letter>| <identifier><letter> | <identifier><digit> |
위의 3줄이 프로그램 언어의 식별자를 설명 할 수 있다.
→ 특수 기호인'::='는 '정의된다'를 의미한다. 구문 구조 이름인 좌측이 '::='기호 다음에
따르는 우측으로 대체될 수 있다는 의미이다. 특수 기호인 '|'는 택일을 의미한다. 그러므로
위의 첫 번째 정의는 세 개의 정의가 합쳐진 형태이다. 각 괄호로(< >)로 묶여진 기호는
비단말(nonterminal) 기호이다. BNF 규율로 다시 정의될 대상이라는 것을 의미한다.
각 괄호로 묶이지 않은 기호(A, B 등 바뀌지 않는 기호)는 단말(terminal) 기호라고 하며,
여기에는 각 언어에서 사용되는 알파벳 문자 집합과 예약어가 있다. BNF 표기에서 사용된
특수 기호들(::=, |, < >)은 메타 기호(meta-symbol)라 불린다.
예1) A = 4
A에 4를 넣어라.
A가 식별된다. 이게 문법이 어떻게 맞는지 확인한다.
A를 '컴파일러'가 어디서(<letter>)부터 왔는지 확인한다.
<letter>은 <identifier>에서 왔다.
그러므로 a는 문법이 맞다.(유효한 식별자이다.)
예2) AB = 4
A는 <le>에서 왔다. <le>는 <id>에서 왔다.
B는 <le>에서 왔다.
앞의 <id>(A)와 뒤의 <le>(B)가 만나서 식별자로 인식된다.(<id><le>)
if문장에서 else부분이 선택적으로 나타낼 수 있다면 아래와 같이 EBNF로 표현할 수 있다.
| <if-statement> ::=if <condition> then <statement> [else <statement>] |
메타 기호인'[ ]'는 나타나거나 한 번 나타날 수 있음을 의미한다.
if-statement와 같이 <>에 묶인건 비단말 기호이다. 다시 정의될 대상이기 때문이다.
if, them, else는 단말 기호이다. 무언가로 바뀔일이 없기 때문이다.
수식을 표현해보자.
| <expression ::=<expression> + <expression> | <expression> - <expression> | <expression> * <expression> | <expression> / <expression> |
을 아래와 같이 줄일 수 있다.
| <expression ::=<expression> (+ | - | * | / ) <expression> |
EBNF (Extended Backus – Naur Form) 표기법
- BNF 표기법을 확장하여 보다 읽기 쉽고, 간단하게 표현된 표기법
- BNF보다 추가된 특수한 의미를 갖는 EBNF의 메타 기호
- 반복: { }, { } → 0 번 이상 반복
- 선택: [ ] → 0 또는 1번 선택
- { }, [ ], |, ( ), ::=와 같은 메타 기호를 언어의 terminal로 사용하는 경우,
' | ', ' ::= ' 와 같이 인용부호로 묶어 표현
- Pascal의 부분 언어 시작부를 EBNF로 표현해보자.
| subpascal 시작부에 대한 EBNF |
| <subpascal> ::=program <ident>;<block> . <block> ::=[<const_dcl>][<var_dcl>]{<proc_dcl>} <compound-st>| <const_dcl> ::=const <ident> = <number> {;<ident> = <number> }; <var_dcl> ::=var <ident_list> : <type>{; <ident_list> : <type> }; <ident_list> ::=<ident> {,<ident>} <proc_dcl> ::=procedure <ident>['('<formal_param>')']; <block>; <compound-st> ::=begin <statement> {;<statement>} end |
7줄의 생성 규칙로 정의되어있다.
<subpascal>은 시작기호(start symbol)이다.
<subpascal>은 각각 program, <ident>, ;, <block> 심볼로 바뀐다.
<block>도 역시 우측의 심볼로 바뀐다.
구문 도표(Syntax diagram)
구문에 대한 형식 정의를 하는 방법으로 EBNF 방법 외에 구문 도표를 이용하는 방법이
있는데, 그 형태가 순서도와 유사하다.
- 구문 도표는 그 형태가 순서도와 유사
- 구문 도표는 EBNF 와 일대일 대응
다시 정의될 대상은 네모칸으로 단말 기호는 원이나 타원형으로 표시하고 이들
사이는 지시선으로 연결
- 단말 X
원 x는 원 또는 타원 안에 x로 표기하고 다음 기호를 보기 위해 나가는 지시선을
그린다.

- 비단말 B
사각형 안에 B로 쓰고 단말의 경우와 같이 지시선을 긋는다.
사각형의 내용은 그 안의 이름으로 참조할 수 있다.

- A ::= X1X2 ... Xn
- X1가 비단말 기호인 경우

- X1가 단말 기호인 경우



- EBNF A ::= {α}

- EBNF A ::= [α]

- EBNF A ::= (α1 | α2)β

예) 다음 EBNF를 구문 도표로 바꾸어 보자.
| A ::= x | '('B')' B ::= AC c ::= {+A} |
여기서 x, +, (, )는 단말 기호이며, A, B, C는 비단말 기호를 나타낸다.
위의 방법을 적용하여 각 비단말에 대한 구문 도표를 그리면 다음과 같다.

구문 도표는 EBNF 표기법과 사고 방식이 유사하므로 EBNF로 작성된 문법을
쉽게 구문 도표로 바꿀 수 있다. 한 BNF 표현을 다양한 EBNF로 표현할 수 있는
것과 마찬가지로 같은 문법을 여러 형태의 구문 도표로 표현할 수 있다.
위의 예는 아래와 같이 하나로 표현할 수 있다.

EBNF 표기법에 의해 표현된 Subpascal의 시작부를 구문 도표로 나타내면 다음과 같다.

파스 트리 (parse tree)
원시 프로그램의 문법을 검사하는 과정에서 내부적으로 생성되는 트리 형태의 자료구조
한 표현이 BNF에 의해 작성될 수 있는지 여부를 나타냄
예) 식별자에 대한 BNF를 통해 다음 TEST1에 대한 파스 트리 작성
|
<identifier> ::=<letter>| |
↓

모호성, 결합성 및 우선 순위
- 서로 다른 유도 과정을 거쳐 B33을 생성한다.
<identifier> → <identifier><digit> → <identifier>3 → <identifier><digit>3
→ <identifier>33 → <letter>33 → B33
<identifier> → <identifier><digit> → <identifier><digit><digit>
→ <letter><digit><digit> → B<digit><digit>
→ B3<digit> → B33
이에 대한 파스트리는 다음과 같이 동일하다.

- 하지만 서로 다른 유도가 다른 파스 트리를 구성할 수 있다.
예) 3 - 2 * 5는 다음의 두 가지 유도과정을 가지고 유도된다.
| <exp> ::= <exp> - <exp> | <exp> * <exp> | (<exp>) | <number> <number> ::= <number> <digit> | <digit> <digit> = 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
<exp> → <exp> - <exp>
→ <exp> - <exp> * <exp>
(두 번째 <exp>이 <exp> * <exp>로 대치)
→ <number> - <exp> * <exp>
→ ...
<exp> → <exp> * <exp>
→ <exp> - <exp> * <exp>
(첫 번째 <exp>이 <exp> - <exp>로 대치)
→ <number> - <exp> * <exp>
→ ...
위의 유도과정은 아래의 서로 다른 파스 트리와


두 가지 서로 다른 추상 구문 트리를 만든다.
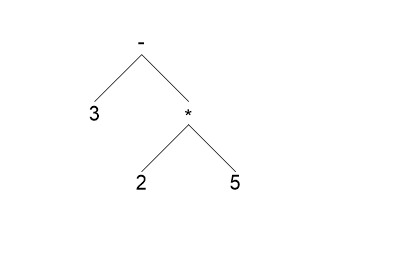

이와 같이 동일 스트링에 대해서 서로 다른 파스 (또는 구문)트리가 발생하면 이러한
문법을 모호(ambiguous)이라고 한다. 모호한 문법은 어떠한 명확한 구조를 표현하지
않기 때문에 어려움을 야기한다.
모호성을 갖는 문법을 유용하게 하려면 문법을 모호함이 없도록 개정하거나, 어떤 구조가
의미 있는지를 결정할 수 있게 *모호성 제거 규칙(disambiguation rule)을 기술해야 한다.
*모호성 제거 규칙: 동일한 어휘 토큰 순서를 가진 다수의 언어 구성자 중 어떤 언어
구성자를 프로그램 내의 특정 사건이 참조하는지 결정하는 행위
- 순위 폭포(precedence cascade): 새 비단말기호(<term>)와 문법
규칙을 추가하여 문법의 우선순위를 정함.
| <exp> ::= <exp> - <exp> | <term> <term> ::= <term> * <term> | (<exp>) | <number> |
하지만 모호성 문제가 완전히 해결된 것은 아님.
7-3-2 파싱 시 동일한 표현이 좌-결합 또는 우-결합의 두 가지로 표현


- BNF 문법에 좌순환 규칙을 사용하면 좌-결합을 지원할 수 있다.
- <exp> ::= <exp> - <exp>를 <exp> ::= <exp>-<term>으로 대치하면
좌-결합으로 파싱된다.

- 우순환 규칙(<exp> ::= <term> - <exp>)을 사용하면 우-결합 파스 트리를 파싱
위의 문법에 지금까지 이야기한 우선순위와 좌-결합을 동시 지원하는 문법은
아래와 같이 될 수 있으며, 이 문법은 모호성을 갖지 않는다.
| <exp> ::= <exp> - <exp> | <exp> * <exp> | (<exp>) | <number> <number> ::= <number> <digit> | <digit> <digit> = 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
↓
| <exp> ::= <exp> - <term> | <term> <term> ::= <term> * <factor> | <factor> <factor> ::= (<exp>) | <number> <number> ::= <number> <digit> | <digit> <digit> = 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
구문과 프로그램 신뢰성
프로그래밍 언어의 구문이 프로그램의 신뢰성을 증대시키는 데 큰 영향을 미치며,
훌륭한 주석(comment)은 프로그램의 문서화에 많은 도움을 준다.
프로그래밍 언어의 구문이 사람과 기계에 의해 쉽게 분석될 수 있도록 한다는 것은
매우 중요하다. 이러한 점에 위배된 여러 가지 예를 보자.
- Fortran문
| DO 10 I = 2.6 A(I) = B + C(I) 10 CONTINUE |
2.6의 오류(. 대신 , 사용해야함)
D010I에 2.6이라는 값을 배정하는 정상적인 배정문으로 인식함
- PL/I문
| A = B = C |
다중배정문의 의미(A와 B에 C값 저장)
(B = C)의 결과를 A에 저장하는 문장으로 인식함
- 현수(dangling) else 문제
중첩된 if문에서 else는 어떤 if의 else인가?
아래의 예를 보자.
| if c1 then if c2 then S1 else S2 |
위의 문장의 모호성으로 인해 다음과 같은 두 가지 의미를 가질 수 있다.
1.
| if c1 then (if c2 then S1 else S2) |
2.
| if c1 then (if c2 then S1) else S2 |
해결방안
| 언어별 현수 else 문제의 해결 방안 |
| Algol60: 1의 경우 if c1 then begin if c2 then S1 else S2 end 2의 경우 if c1 then begin if c2 then S1 end else S2 Algol68: 1의 경우 if c1 then if c2 then S1 else S2 fi fi 2의 경우 if c1 then if c2 then S1 fi else S2 fi PL/I: 2의 경우 IF c1 THEN IF c2 THEN S1;ELSE S2; 또는 IF c1 THEN IF c2 THEN S1;ELSE;ELSE S2; Pascal: 2의 경우 if c1 then begin if c2 then S1 end else S2 또는 if c1 then if c2 then S1 else else S2 *PL/1과 Pascal에서 일반적으로 사용된 경우 1의 경우로 해석됨 |
'공부 > 프로그래밍언어론' 카테고리의 다른 글
| 프로그래밍 언어 구현 기법 (0) | 2020.04.28 |
|---|---|
| 프로그래밍 언어 설계 (0) | 2020.04.26 |
| 프로그래밍 언어의 세대론과 미래 (0) | 2020.04.26 |
| 1990년대: 웹(WWW)을 위한 언어 (0) | 2020.04.25 |
| 1970년대: 간결성, 추상화, 연구 사항 (0) | 2020.04.25 |
